Pipeline
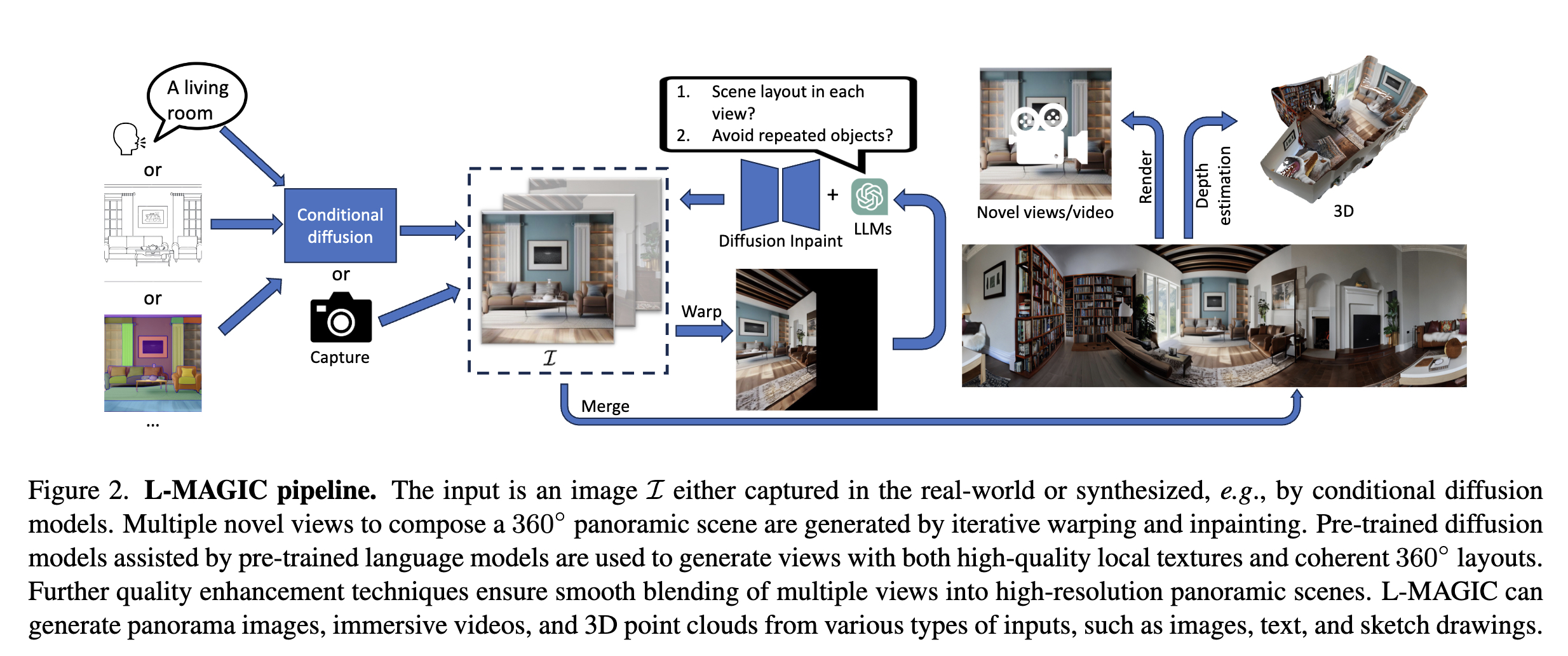
In the current era of generative AI breakthroughs, generating panoramic scenes from a single input image remains a key challenge. Most existing methods use diffusion-based iterative or simultaneous multi-view inpainting. However, the lack of global scene layout priors leads to subpar outputs with duplicated objects (e.g., multiple beds in a bedroom) or requires time-consuming human text inputs for each view. We propose L-MAGIC, a novel method leveraging large language models for guidance while diffusing multiple coherent views of 360 degree panoramic scenes. L-MAGIC harnesses pre-trained diffusion and language models without fine-tuning, ensuring zero-shot performance. The output quality is further enhanced by super-resolution and multi-view fusion techniques. Extensive experiments demonstrate that the resulting panoramic scenes feature better scene layouts and perspective view rendering quality compared to related works, with >70% preference in human evaluations. Combined with conditional diffusion models, L-MAGIC can accept various input modalities, including but not limited to text, depth maps, sketches, and colored scripts. Applying depth estimation further enables 3D point cloud generation and dynamic scene exploration with fluid camera motion.


















@inproceedings{zhipeng2024lmagic,
title={L-MAGIC: Language Model Assisted Generation of Images with Coherence},
author={Zhipeng Cai and Matthias Müller and Reiner Birkl and Diana Wofk and Shao-Yen Tseng and JunDa Cheng and Gabriela Ben-Melech Stan and Vasudev Lal and Michael Paulitsch},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}